Automatic Properties If you are a C# developer today, you are probably quite used to writing classes with basic properties like the code-snippet below:
public class Person {
private string _firstName; private string _lastName; private int _age;
public string FirstName {
get { return _firstName; } set { _firstName = value; } }
public string LastName {
get { return _lastName; } set { _lastName = value; } }
public int Age {
get { return _age; } set { _age = value; } } }
Note about that we aren't actually adding any logic in the getters/setters of our properties - instead we just get/set the value directly to a field. This begs the question - then why not just use fields instead of properties? Well - there are a lot of downsides to exposing public fields. Two of the big problems are: 1) you can't easily databind against fields, and 2) if you expose public fields from your classes you can't later change them to properties (for example: to add validation logic to the setters) without recompiling any assemblies compiled against the old class.
The new C# compiler that ships in "Orcas" provides an elegant way to make your code more concise while still retaining the flexibility of properties using a new language feature called "automatic properties". Automatic properties allow you to avoid having to manually declare a private field and write the get/set logic -- instead the compiler can automate creating the private field and the default get/set operations for you.
For example, using automatic properties I can now re-write the code above to just be:
public class Person {
public string FirstName { get; set; }
public string LastName { get; set; }
public int Age { get; set; } }
Or If I want to be really terse, I can collapse the whitespace even further like so:
public class Person { public string FirstName { get; set; } public string LastName { get; set; } public int Age { get; set; } }
When the C# "Orcas" compiler encounters an empty get/set property implementation like above, it will now automatically generate a private field for you within your class, and implement a public getter and setter property implementation to it. The benefit of this is that from a type-contract perspective, the class looks exactly like it did with our first (more verbose) implementation above. This means that -- unlike public fields -- I can in the future add validation logic within my property setter implementation without having to change any external component that references my class.
Object Initializers
Types within the .NET Framework rely heavily on the use of properties. When instantiating and using new classes, it is very common to write code like below:
Person person = new Person(); person.FirstName = "Scott"; person.LastName = "Guthrie"; person.Age = 32;
Have you ever wanted to make this more concise (and maybe fit on one line)? With the C# and VB "Orcas" compilers you can now take advantage of a great "syntactic sugar" language feature called "object Initializers" that allows you to-do this and re-write the above code like so:
Person person = new Person { FirstName="Scott", LastName="Guthrie", Age=32 };
The compiler will then automatically generate the appropriate property setter code that preserves the same semantic meaning as the previous (more verbose) code sample above.
In addition to setting simple property values when initializing a type, the object initializer feature allows us to optionally set more complex nested property types. For example, assume each Person type we defined above also has a property called "Address" of type "Address". We could then write the below code to create a new "Person" object and set its properties like so:
Person person = new Person { FirstName = "Scott", LastName = "Guthrie" Age = 32, Address = new Address { Street = "One Microsoft Way", City = "Redmond", State = "WA", Zip = 98052 } };
Collection Initializers
Object Initializers are great, and make it much easier to concisely add objects to collections. For example, if I wanted to add three people to a generics-based List collection of type "Person", I could write the below code:
List people = new List();
people.Add( new Person { FirstName = "Scott", LastName = "Guthrie", Age = 32 } ); people.Add( new Person { FirstName = "Bill", LastName = "Gates", Age = 50 } ); people.Add( new Person { FirstName = "Susanne", LastName = "Guthrie", Age = 32 } );
Using the new Object Initializer feature alone saved 12 extra lines of code with this sample versus what I'd need to type with the C# 2.0 compiler.
The C# and VB "Orcas" compilers allow us to go even further, though, and also now support "collection initializers" that allow us to avoid having multiple Add statements, and save even further keystrokes:
List people = new List { new Person { FirstName = "Scott", LastName = "Guthrie", Age = 32 }, new Person { FirstName = "Bill", LastName = "Gates", Age = 50 }, new Person { FirstName = "Susanne", LastName = "Guthrie", Age = 32 } };
When the compiler encounters the above syntax, it will automatically generate the collection insert code like the previous sample for us.
PowerCommands is a set of useful extensions for the Visual Studio 2008 adding additional functionality to various areas of the IDE. The source code is included and requires the VS SDK for VS 2008 to allow modification of functionality or as a reference to create additional custom PowerCommand extensions. Visit the VSX Developer Center at http://msdn.com/vsx for more information about extending Visual Studio.
The Releases page contains download files (MSI installation file, readme document, and source code project).
Below is a list of the included in PowerCommands for Visual Studio 2008 version 1.0. Refer to the Readme document which includes many additional screenshots.
Collapse Projects This command collapses a project or projects in the Solution Explorer starting from the root selected node. Collapsing a project can increase the readability of the solution. This command can be executed from three different places: solution, solution folders and project nodes respectively.
Copy Class This command copies a selected class entire content to the clipboard, renaming the class. This command is normally followed by a Paste Class command, which renames the class to avoid a compilation error. It can be executed from a single project item or a project item with dependent sub items.
Paste Class This command pastes a class entire content from the clipboard, renaming the class to avoid a compilation error. This command is normally preceded by a Copy Class command. It can be executed from a project or folder node.
Copy References This command copies a reference or set of references to the clipboard. It can be executed from the references node, a single reference node or set of reference nodes.
Paste References This command pastes a reference or set of references from the clipboard. It can be executed from different places depending on the type of project. For CSharp projects it can be executed from the references node. For Visual Basic and Website projects it can be executed from the project node.
Copy As Project Reference This command copies a project as a project reference to the clipboard. It can be executed from a project node.
Edit Project File This command opens the MSBuild project file for a selected project inside Visual Studio. It combines the existing Unload Project and Edit Project commands.
Open Containing Folder This command opens a Windows Explorer window pointing to the physical path of a selected item. It can be executed from a project item node
Open Command Prompt This command opens a Visual Studio command prompt pointing to the physical path of a selected item. It can be executed from four different places: solution, project, folder and project item nodes respectively.
Unload Projects This command unloads all projects in a solution. This can be useful in MSBuild scenarios when multiple projects are being edited. This command can be executed from the solution node.
Reload Projects This command reloads all unloaded projects in a solution. It can be executed from the solution node.
Remove and Sort Usings This command removes and sort using statements for all classes given a project. It is useful, for example, in removing or organizing the using statements generated by a wizard. This command can be executed from a solution node or a single project node. Note: The Remove and Sort Usings feature is only available for C# projects since the C# editor implements this feature as a command in the C# editor (which this command calls for each .cs file in the project).
Extract Constant This command creates a constant definition statement for a selected text. Extracting a constant effectively names a literal value, which can improve readability. This command can be executed from the code editor by right-clicking selected text.
Clear Recent File List This command clears the Visual Studio recent file list. The Clear Recent File List command brings up a Clear File dialog which allows any or all recent files to be selected.
Clear Recent Project List This command clears the Visual Studio recent project list. The Clear Recent Project List command brings up a Clear File dialog which allows any or all recent projects to be selected.
Transform Templates This command executes a custom tool with associated text templates items. It can be executed from a DSL project node or a DSL folder node.
Close All This command closes all documents. It can be executed from a document tab.
With the past few releases of Visual Studio, each Visual Studio release only supported a specific version of the .NET Framework. For example, VS 2002 only worked with .NET 1.0, VS 2003 only worked with .NET 1.1, and VS 2005 only worked with .NET 2.0.
One of the big changes we are making starting with the VS 2008 release is to support what we call "Multi-Targeting" - which means that Visual Studio will now support targeting multiple versions of the .NET Framework, and developers will be able to start taking advantage of the new features Visual Studio provides without having to always upgrade their existing projects and deployed applications to use a new version of the .NET Framework library.
Now when you open an existing project or create a new one with VS 2008, you can pick which version of the .NET Framework to work with - and the IDE will update its compilers and feature-set to match this. Among other things, this means that features, controls, projects, item-templates, and assembly references that don't work with that version of the framework will be hidden, and when you build your application you'll be able to take the compiled output and copy it onto a machine that only has an older version of the .NET Framework installed, and you'll know that the application will work.
Creating a New Project in VS 2008 that targets .NET 2.0
To see an example of multi-targeting in action on a recent build of VS 2008 Beta 2, we can select File->New Project to create a new application.
Notice below how in the top-right of the new project dialog there is now a dropdown that allows us to indicate which versions of the .NET Framework we want to target when we create the new project. If I keep it selected on .NET Framework 3.5, I'll see a bunch of new project templates listed that weren't in previous versions of VS (including support for WPF client applications and WCF web service projects):
If I change the dropdown to target .NET 2.0 instead, it will automatically filter the project list to only show those project templates supported on machines with the .NET 2.0 framework installed:
If I create a new ASP.NET Web Application with the .NET 2.0 dropdown setting selected, it will create a new ASP.NET project whose compilation settings, assembly references, and web.config settings are configured to work with existing ASP.NET 2.0 servers:
When you go to the control Toolbox, you'll see that only those controls that work on ASP.NET 2.0 are listed:
And if you choose Add->Reference and bring up the assembly reference picker dialog, you'll see that those .NET class assemblies that aren't supported on .NET 2.0 are grayed out and can't be added to the project (notice how the "ok" button is not active below when I have a .NET 3.0 or .NET 3.5 assembly selected):
So why use VS 2008 if you aren't using the new .NET 3.5 features?
You might be wondering: "so what value do I get when using VS 2008 to work on a ASP.NET 2.0 project versus just using my VS 2005 today?" Well, the good news is that you get a ton of tool-specific value with VS 2008 that you'll be able to take advantage of immediately with your existing projects without having to upgrade your framework/ASP.NET version. A few big tool features in the web development space I think you'll really like include:
JavaScript intellisense
Much richer JavaScript debugging
Nested ASP.NET master page support at design-time
Rich CSS editing and layout support within the WYSIWYG designer
Split-view designer support for having both source and design views open on a page at the same time
A much faster ASP.NET page designer - with dramatic perf improvements in view-switches between source/design mode
Automated .SQL script generation and hosting deployment support for databases on remote servers
You'll be able to use all of the above features with any version of the .NET Framework - without having to upgrade your project to necessarily target newer framework versions. I'll be blogging about these features (as well as the great new framework features) over the next few weeks.
So how can I upgrade an existing project to .NET 3.5 later?
If at a later point you want to upgrade your project/site to target the NET 3.0 or NET 3.5 version of the framework libraries, you can right-click on the project in the solution explorer and pull up its properties page:
You can change the "Target Framework" dropdown to select the version of the framework you want the project to target. Doing this will cause VS to automatically update compiler settings and references for the project to use the correct framework version. For example, it will by default add some of the new LINQ assemblies to your project, as well as add the new System.Web.Extensions assembly that ships in .NET 3.5 which delivers new ASP.NET controls/runtime features and provides built-in ASP.NET AJAX support (this means that you no longer need to download the separate ASP.NET AJAX 1.0 install - it is now just built-in with the .NET 3.5 setup):
Once you change your project's target version you'll also see new .NET 3.5 project item templates show up in your add->new items dialog, you'll be able to reference assemblies built against .NET 3.5, as well as see .NET 3.5 specific controls show up in your toolbox.
For example, below you can now see the new control (which is an awesome new control that provides the ability to do data reporting, editing, insert, delete and paging scenarios - with 100% control over the markup generated and no inline styles or other html elements), as well as the new control (which enables you to easily bind and work against LINQ to SQL data models), and control show up under the "Data" section of our toolbox:
Note that in addition to changing your framework version "up" in your project properties dialog, you can also optionally take a project that is currently building against .NET 3.0 or 3.5 and change it "down" (for example: move it from .NET 3.5 to 2.0). This will automatically remove the newer assembly references from your project, update your web.config file, and allow you to compile against the older framework (note: if you have code in the project that was written against the new APIs, obviously you'll need to change it).
What about .NET 1.0 and 1.1?
Unfortunately the VS 2008 multi-targeting support only works with .NET 2.0, .NET 3.0 and .NET 3.5 - and not against older versions of the framework. The reason for this is that there were significant CLR engine changes between .NET 1.x and 2.x that make debugging very difficult to support. In the end the costing of the work to support that was so large and impacted so many parts of Visual Studio that we weren't able to add 1.1 support in this release.
VS 2008 does run side-by-side, though, with VS 2005, VS 2003, and VS 2002. So it is definitely possible to continue targeting .NET 1.1 projects using VS 2003 on the same machine as VS 2008.
The DataBinder.Eval method uses .NET reflection to evaluate the arguments that are passed in and to return the results. Consider limiting the use of DataBinder.Eval during data binding operations in order to improve ASP.NET page performance.
Consider the following ItemTemplate element within a Repeater control using DataBinder.Eval:
When you create an ADO.NET DataReader object, specify the CommandBehavior.CloseConnection enumeration in your call to ExecuteReader. This ensures that when you close the DataReader, the SQL connection is also closed. This is especially helpful when you return a DataReader from a function, and you do not have control over the calling code. If the caller forgets to close the connection but closes the reader, both are closed when the DataReader is created by using CommandBehavior.CloseConnection. This is shown in the following code fragment.
publicSqlDataReader CustomerRead(int CustomerID)
{
//... create connection and command, open connection
I often need to open Windows Explorer and browse to the current file, folder, or project that I am working on in Visual Studio. This tip allows you to achieve this by clicking "Windows Explorer" in the Tools menu, and is one of the most simple-yet-useful tips I know of.
To set it up, click Tools, then External Tools..., then click Add. Now enter the following data: Title: Windows Explorer Command: explorer.exe Arguments: /select,"$(ItemPath)"
Leave Initial directoy blank, and click OK. Now when you click Tools, Windows Explorer, Windows Explorer will open with the current file you are editing selected.
AJAX opens many interesting new doors in terms of how we can tailor the user experience to the customers needs and how we can display content based on any number of state context.
This sometimes means fetching and manipulating HTML or XML in our server side code and sending it to the browser as execution time via an AJAX request.
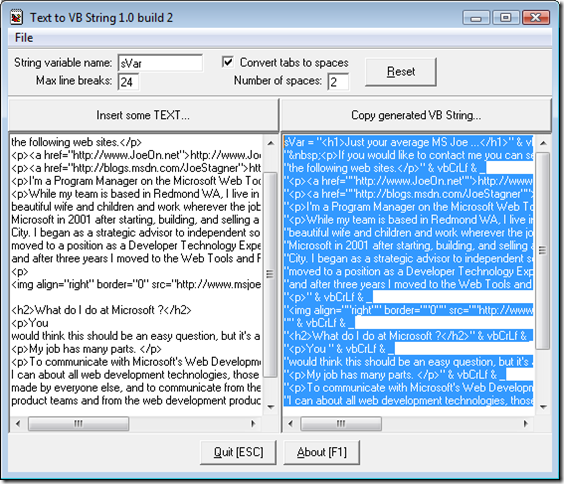
This is the best utility which convert your Text/ HTML code in String that we can utilize at server side code.
Learn when and how to utilize Windows Communication Foundation to develop and maintain your communications layer when creating a loosely coupled, scalable, interoperable services-oriented application.
Technology Toolbox: C#, Other: Windows Communication Foundation
Windows Communication Foundation (WCF) is a powerful new technology for building services-oriented architecture (SOA)-based applications. The usefulness of WCF goes well beyond large-scale enterprise SOAs. WCF can be used even for simple scenarios where all you need is connectivity between two apps on the same machine or across processes on different machines, even if you haven't adopted the full architectural approach of SOA.
In this article, I'll discuss some best practices and things to keep in mind when applying WCF in the real world. I'll start with a quick review of the basics of connecting applications with WCF, and then focus on several areas where you have to make hard choices between creating an easy-to-develop-and-maintain communications layer or creating a loosely coupled, scalable, interoperable SOA-based application. I'll also emphasize a collection of best practices, describing the context of where those practices would apply and why they're important.
You can use WCF to get two different chunks of code talking to each other across a wide variety of connectivity scenarios. With WCF, you can create a full-blown SOA-based application that communicates across the open Internet with another service written in a completely different technology. You can also use it to get two classes in the same assembly in the same process talking to one another. In general, you should consider using WCF for any new code where you need to cross a process boundary, and even in some scenarios for connecting decoupled objects (as services) within the same process. Basically, you should forget that .NET Remoting, ASP.NET Web Services, and Enterprise Services exist (except for maintaining legacy code written in those technologies), and focus on WCF for all your connectivity needs.
Connecting two pieces of code with WCF requires that you implement five elements on the server side.
First, you need a service contract. This defines what operations you expose at the service boundary, as well as the data that is passed through those operations.
Second, you need data contracts for complex types passed through the service contract operations. These contracts define the shape of the sent data so that it can be consumed or produced by the client.
Third, you need a service implementation. This provides the functional code that answers the incoming service messages and decides what to do with them.
The fourth required element is a service configuration. This specifies how the service is exposed, in terms of its address, binding, and contract. Wrapped up in the binding are all the gory details of what network protocol you're using, the encoding of the message, the security mechanisms being used, and whether you're using reliability, transactions, or several other features that WCF supports.
Finally, you must have a service host. This is the process where the service runs. Your service host can be any .NET process if you want to self-host it, IIS, or Windows Activation Service (WAS) for Windows Vista and Windows Server 2008.
On the client side, you need to implement three different technologies to make service calls with WCF (whether the service is a WCF service or one implemented in some other technology): a service contract definition that matches what the server uses, a data contract definition that matches what the server is using, and a proxy that can form the messages to send to the service and process returned messages.
There are many different ways that you can use WCF, depending on the scenario and requirements; however, there are a number of best practices you should keep in mind as you design your WCF back-end services.
Use Service Boundary Best Practices Layering is a good idea in any application. You should already be familiar with the benefits of separating functionality into a presentation layer, business layer, and data access layer. Layering provides separation of concerns and better factoring of code, which gives you better maintainability and the ability to split layers out into separate physical tiers for scalability. In the same way that data access code should be separated into its own layer that focuses on translating between the world of the database and the application domain, services should be placed in a separate service layer that focuses on translating between the services-oriented external world and the application domain (see Figure 1).
Having a service layer implies that you've put your service definitions into a separate class library, and host that library in your service host environment. The service layer dispatches calls into the business layer to get the work of the service operation done.
WCF supports putting your service contract and operation contract attributes directly in the implementation class, but you should always avoid doing so. Having an interface definition that clearly defines what the service boundary looks like, separate from the implementation of that service, is preferable.
For example, you might implement a simple service contract definition like this:
[ServiceContract()] public interface IProductService { [OperationContract()] List GetProducts(); }
An important aspect of SOA design is hiding all the details of the implementation behind the service boundary. This includes revealing or dictating what particular technology was used. It also means you shouldn't assume the consuming application supports a complex object model. Part of the service boundary definition is the data contract definition for the complex types that will be passed as operation parameters or return values.
For maximum interoperability and alignment with SOA principles, you should not pass .NET-specific types, such as DataSets or Exceptions, across the service boundary. You should stick to fairly simple data structure objects such as classes with properties and backing member fields. You can pass objects that have nested complex types such as a Customer with an Order collection, but you shouldn't make any assumptions about the consumer being able to support object-oriented constructs like interfaces or base classes for interoperable Web services.
However, if you're using WCF only as a new remoting technology to get two different pieces of code to talk to each other across processes, with no expectation or requirement for others to write consuming applications, then you can pass whatever you want as a data contract. You just have to make sure that those types are marked appropriately as data contracts or are serializable types. Generally speaking, you face various challenges when passing DataSets through WCF services, so you should avoid doing so, except for simple scenarios. If you do want to pursue using DataSets with WCF, you should definitely use typed DataSets and try to stick to individualy typed DataTables as parameters or return types.
Note that the simple service contract described previously is defined in terms of List. WCF is designed to flatten enumerable collections into arrays at the service boundary. Rather than limiting interoperability, this feature makes your life easier when populating and using your collections in the service and business layers.
For example, consider this data contract definition for the ConsumerProduct type:
[DataContract()] public class ConsumerProduct { private int m_ProductID; private string m_ProductName; private double m_UnitPrice;
[DataMember()] public int ProductID { get { return m_ProductID; } set { m_ProductID = value; } }
[DataMember()] public string ProductName { get {return m_ProductName; } set{ m_ProductName = value; } }
[DataMember()] public double UnitPrice { get {return m_UnitPrice; } set { m_UnitPrice = value; } } }
Use Per-Call Instancing Another important best practice to adhere to: Services should use per-call instancing as a default. WCF supports three instancing modes for services: Per-Call, Per-Session, and
Single. Per-Call creates a new instance of the service implementation class for each operation call that comes into the service and disposes of it when the service operation is
complete. This is the most scalable and robust option, so it's unfortunate that the WCF product team decided to change from this being the default instancing mode shortly before release of the product. Per-Session allows a single client to keep a service instance alive on the server as long as the client keeps making calls into that instance. This allows you to store state in member variables of the service instance between calls and have an ongoing, stateful conversation between a client application and a server object. However, it has several messy side effects, including the fact that consuming memory on a server when it isn't actively in use is bad for scalability. It also gets messy when transactions are involved. Single(ton) allows you to have all calls from all clients routed to a single service instance on the back-end. This allows you to use that single point of entry as a gatekeeper if your requirements dictate the need for such a thing. Using the Singleton mode is even worse for scalability because all calls into the singleton instance are serialized (one caller at a time) by default. Single mode also has some of the same side effects as sessionful services. That said, there are specific scenarios where using Per-Session or Single makes sense.
You should try to design your services as Per-Call initially because it's the cleanest, most scalable, and safest option, and only talk yourself into using Per-Session or Singleton if you understand the implications of using those modes.
This code declares a Per-Call service for the service contract illustrated previously:
[ServiceBehavior( InstanceContextMode= InstanceContextMode.PerCall)] public class ProductService : IProductService { List IProductService.GetProducts() { ... } }
I recommend checking out "Programming WCF Services" by Juval Löwy (O'Reilly, 2007) for a better understanding of the differences between--and implications of--Per-Session and Single instancing modes (see Additional Resources).
Deal with Exceptions If an unhandled exception reaches the service boundary, WCF will catch that exception and return a SOAP fault to the caller. By default, that fault is opaque and doesn't reveal any details about what the real problem was on the back-end. This is good and aligns with SOA design principles. You should only reveal information to the client that you choose to expose, and avoid exposing details like stack traces and the like that would go with a normal exception delivery.
However, for most bindings in WCF, WCF will also fault the channel when an unhandled exception reaches the service boundary, which usually means you cannot make subsequent calls through the same proxy on the client side, and you will have to establish a new connection to the server. As a result, one of your responsibilities in designing a good service layer is to catch all exceptions and throw a FaultException exception to WCF in cases when the service could recover from the exception and answer subsequent calls without causing follow-on problems.
FaultException is a special type that still propagates as an Exception on the .NET call stack, but is interpreted differently by the WCF layer that performs the messaging. Think of it as a handled exception that you're throwing to WCF, as opposed to an unhandled exception that propagates into WCF on its own without your service intervening. You can pass non-detailed information to the client about what the problem was by using the Reason property on FaultException. If a FaultException is caught by WCF, it will still package it as a SOAP fault message, but it will not fault the channel. That means you can instruct the client to handle the resulting error and keep calling the service without needing to open a new connection.
There are many different scenarios for dealing with exceptions in WCF, as well as several ways to hook up your exception handling in the service layer.
Some basic rules you should follow include: Catch unhandled exceptions and throw a FaultException if your service is able to recover and answer subsequent calls without causing further problems (which it should be able to do if you designed it as a per-call service); don't send exception details to the client except for debugging purposes during development; and pass non-detailed exception information to the client using the Reason property on FaultException.
This service method captures a particular exception type and returns non-detailed information about the problem to the client through FaultException:
List IProductService.GetProducts() { try { ... } catch (SqlException ex) { throw new FaultException( "The service could not connect to the data store", // details argument "Unknown error"); // Reason } }
The T type parameter can be any type you want, but for interoperability, you will probably want to stick to a simple data structure that is marked as a data contract or types that are serializable.
For small-scale services where you will be the only one writing the client applications, you can choose to wrap the caught exception type in a FaultException (for example, FaultException) so that the client gets the full details of the exception, but you don't fault the channel.
Michele Leroux Bustamante's book, "Learning WCF" (O'Reilly, 2007), provides good coverage of exception handling in WCF (see Additional Resources).
Choose an Appropriate Service Host Windows Communication Foundation has three options for hosting your services. You can be self-hosted (run your services in any .NET application that you design), IIS-hosted, or Windows Activation Service (WAS)-hosted.
Self-hosting gives you the most flexibility because you set up the hosting environment yourself. This means you can access and configure your service host programmatically and do other things like hook up to service host events for operations monitoring and control. However, self-hosting puts the responsibility for process management and other configuration options squarely on your shoulders.
This code describes a simple Windows Service self-hosting setup:
public partial class MyNTServiceHost : ServiceBase { ServiceHost m_ProductServiceHost = null; public MyNTServiceHost() { InitializeComponent(); } protected override void OnStart(string[] args) { m_ProductServiceHost = new ServiceHost(typeof(ProductService)); m_ProductServiceHost.Open(); }
IIS-hosting allows you to deploy your services to IIS by dropping the DLLs into the \Bin directory and putting .SVC files as the service addressable endpoints. You gain the kernel-level request routing of IIS, the IIS management consoles for configuring the hosting environment, IIS's ability to start and recycle worker processes, and more. The big downside to IIS-hosting is that you're stuck with HTTP-based bindings only.
WAS is a part of IIS 7 (Windows Vista and Windows Server 2008) and gives you the hosting model of IIS. However, it also allows you to expose services using protocols other than HTTP, such as TCP, Named Pipes, and MSMQ.
WAS is almost always the best choice if you're targeting newer platforms. If you're exposing services outside your network, you will probably be using HTTP protocols anyway, so IIS-hosting is usually best for externally exposed services.
If WAS-hosting isn't an option for services running inside the intranet, you should plan on self-hosting to take advantage of other (faster and more capable) protocols inside the firewall, as well as to give you more flexibility when configuring your environment programmatically.
Use Callbacks Properly WCF includes a capability to call back a client to return data to it asynchronously or as a form of event notification. This is handy when you want to signal the client that a long-running operation has completed on the back-end, or to notify a client of changing data that affects it. To do this, you must define a callback contract that is paired with your service contract. The client doesn't have to expose that callback contract publicly as a service to the outside world, but the service can use it to call back to the client after an initial call has been made into the service by the client. This code creates a service contract definition with a paired callback contract:
[ServiceContract(CallbackContract =typeof(IProductServiceCallback))] public interface IProductService { [OperationContract()] List GetProducts();
public interface IProductServiceCallback { [OperationContract()] void ProductChanged(ConsumerProduct product); }
If you intend to use callbacks, it's a good idea to expose a subscribe/unsubscribe API as part of the service contract. To perform callbacks, the service must capture a callback context from an incoming call, and then hold that context in memory until the point when a call is made back to the client. The client also needs to create an object that implements the callback interface to receive the incoming calls from the service, and must keep that object and the same proxy alive as long as callbacks are expected. This sets up a fairly tightly coupled communications pattern between the client and the service (including object lifetime dependencies), so it's a good idea to let the client control exactly when that tight coupling begins and ends through explicit service calls to start and end the conversation.
The biggest limitations of callbacks are that they don't scale and might not work in interop scenarios. The scaling problem is related to the fact that the service must hold a reference to the client in memory and perform the callbacks on that reference. Listing 1 contains code that illustrates how to capture, store, and change notification to the client through a callback reference for a service.
You also face an interop problem related to the fact that the callback mechanism in WCF is based on a proprietary technology with no ratified standard. It's proprietary, but at least it's expressed through things in the SOAP message that could be consumed and used properly by other technologies. However, if interop is a part of your requirements, you should avoid callbacks.
The alternatives are to set up a polling API where a client can come and ask for changes at appropriate intervals, or you can set up a publish-subscribe middleman service to act as a broker for subscriptions and publications to avoid coupling the client and the service and to keep them scalable. You can find an example of how to do this in the appendix of "Programming WCF Services" (see Additional Resources).
Use Maintainable Proxy Code One of the tenets of service orientation is that you should share schema and contract, not types. So, to keep a client as decoupled as possible from a service definition, you shouldn't share any types between the service and the client that aren't part of the service boundary. However, if you're writing both the service and the client, you don't want to have to maintain two type definitions for the same thing.
That said, there's no crime in referencing an assembly on the client side that's also used by the service to access the .NET type definitions of the service contract and data contracts. You just have to make sure that your service is usable by clients if they don't have access to the shared assembly, rather than having to regenerate those types on the client side from the metadata. To do so, just define these in a separate assembly from the service implementation so that you can reference them from both sides without introducing additional coupling. If you do this, keep in mind that you're introducing a little more coupling between service and client in the interest of productivity and speed of development and maintenance.
As mentioned in the earlier section on faults, an unhandled exception delivered as a fault will also fault the communications channel with most of the built-in bindings. When the fault is received in a WCF client, it's raised as a FaultException if it wasn't specifically thrown as a FaultException on the service side. Because it's not consistent across all bindings, and because your service code and client code should be decoupled from whatever particular binding you use, the only safe thing to do on the client side if a service call throws an exception is to assume the worst and avoid re-using the proxy. In fact, even disposing of or closing the proxy can result in a subsequent exception. This means you should wrap calls to a service in try/catch blocks and replace the proxy instance with a new one in the catch block:
public class MyClient { ProductServiceClient m_Proxy = new ProductServiceClient();
That's about it for taking advantage of WCF in the real world. I've covered a lot of ground, including many of the constructs you will need to define WCF services and clients. I've also discussed how best practices and real-world considerations affect the choices you make for those constructs. Of course, this is just a start; the real way to absorb these lessons is to sit down at a keyboard and give them a go. To that end, the sample code for this article includes a full implementation of a service and client that calls that service with all the basic code constructs. Feel free to give the code a whirl and experiment with it to get a better feel for how the technologies in this article fit together.
There's a lot that LINQ to SQL (formerly called Dlinq) can offer developers, and in this Q&A preview of his session, Birch outlines what's new, shares some of his favorite LINQ to SQL features and more.
What do you think are the top benefits for using LINQ to SQL?
BIRCH: There are two primary benefits that I enjoy when using LINQ to SQL, the first one being the ease of transition for people moving from standard T-SQL query syntax to this new method of data retrieval. Both LINQ to SQL and T-SQL have very similar syntax and command results. It is also easy to create the mapping files that are used.
The second benefit is that LINQ to SQL derives from LINQ, which means that the techniques and syntax used to query for data becomes very similar in nature to querying for objects, XML and any other LINQ-enabled data source.
What's your favorite LINQ to SQL feature/tool?
B: It really depends on the type of project I'm working on. For small and prototype projects, I really love the domain-specific language designer and code generation found in SQL Metal, simply because it is a pretty trick. However, when I'm looking at building a bigger, tiered application, I tend to shy away from all the attribute markup that is engrained into the class definitions; then, my second favorite feature (and the real reason to use LINQ to SQL) is the T-SQL generation. For anyone who is a db mapping enthusiast like me and hasn't yet looked into these, I highly recommend digging into the Binary Execution Trees which "LINQ to N" engines use to map to the various data stores.
When you first started using LINQ to SQL, was there anything that surprised you?
B: I would say the biggest "hmm..." moments for me were related to disconnecting and reconnecting objects to the Data Context. I typically try to wrap the data calls into one or more interface contract(s) and pipe the data to the caller using serialized data via services. The problem is in the deserialization and reconnection of the object to the Data Context for create and update operations. I'll be using one workaround in my presentation at VSLive! 2008 at the end of March so I don't want to give too much away...Seriously, though, there are a few valid approaches to getting around this issue depending on your requirements/code style that are pretty easy to find if you search for them.
For users of LINQ to SQL's predecessor ObjectSpaces, what are the biggest differences that they should be aware of?
B: The best way to clarify the differences between Object Spaces and LINQ to SQL is by showing the code. For example, to add a given object to an object spaces mapper you would use syntax like the following:
There are a couple key elements to point out with this syntax. First, notice that the result type is not explicitly cast and requires a (Animal) boxing operation and a typeof(Animal) to specify the expected return type. Second, notice the list of parameters being passed into the create call.
An example of similar functionality using LINQ to SQL looks something like this:
// This is now just a helper method public void addAnimal(string Species, string Age, string Weight) { Animal animal = new Animal(); animal.Species = Species; animal.Age = Age; animal.Weight = Weight; // Call to the actual add method addAnimal(animal); }
public void addAnimal(Animal animal) { ZooDataContext dc = new ZooDataContext(); dc.Animals.Add(animal); dc.SubmitChanges(); }
It looks like more code but the rest of the app would be using the Animal POCO (plain ol' CLR objects), so most calls would now be using objects and one could simply use the new object instantiation method to create the object and forego the helper method entirely:
Animal animal = new Animal { Species = "Feline", Age = 5, Weight = 100 }; addAnimal(animal);
Another and even more critical distinction comes when querying for objects. In ObjectSpaces the query filter has to be provided to the engine. This requires strict convention adherence and/or domain knowledge in order to create the queries. You may see something akin to the following:
The developer writing this code has to know that the key field in the DB is named ID and any, more complicated filters require even more pre-knowlege of the database schema. In LINQ you would be using intellisense and type safe criteria to specify the filter:
var animal = dc.Animals.Single(a => a.ID == ID).SingleOrDefault();
Coming from a heavy SQL background and having created many cross-domain filtering methods, I really appreciate the flexibility, safety and simplicity of the new syntax.
Do you have a favorite LINQ to SQL tip you could share with our readers?
B: The only thing I can really say is to jump in and start playing with this stuff. If you want a quick "up to speed" kind of experience, a good friend of mine, Daniel Egan, recently recorded a presentation where he goes into some pretty good depth on all the stuff behind LINQ to SQL and even shows some good intro code off. The link to that presentation can be found here.
What, if any, downsides do you feel LINQ to SQL has?
B: Right now, the two biggest downsides to LINQ to SQL is the lack of support for complex type mapping which, in most cases, precludes it from being very useful for legacy databases. Also, the current implementation of LINQ to SQL is, as the name implies, limited to mapping to a SQL Server Database, which means that all of the Oracle guys out there are missing out. The upside is that the LINQ semantics allow the creation of LINQ to Oracle.
Besides LINQ to SQL, what else in LINQ would you encourage developers to learn more about right away?
B: The first step is to jump in and start playing with the new language features. Besides saving a lot of typing, when used properly, they can help you to more clearly express your code's intent.
If you haven't done so already, start using more delegates and play around with the anonymous methods. Once you have those two concepts down, you can start refactoring your code down to lambda expressions, then things start getting really exciting (and confusing for awhile; don't get intimidated).
A habit I picked up when writing lambdas is thinking to myself as I write out the expression. For example:
var myList = new List(); <-- anonymous type!
... Populate the list with a bunch of values ...
var average = myList.Average(c => c.IntegerProperty);
While writing the "c => c.IntegerProperty" I'm thinking something along the lines of:
"c is a ComplexObject and I want the IntegerProperty"
or
"c such that I get the average of all ComplexType's IntegerProperty"
Take advantage of the new keywords associated with C# 3.0's query syntax. Learn how these keywords map to methods defined using the query operands, and how you can define your own custom implementation for the query keywords.
C# 3.0 includes many strong new features, but one of the most interesting is the inclusion of its new query keywords, that you use to create Query Expressions. Query Expressions are most commonly associated with Language Integrated Query (LINQ). They're the core syntax that you'll use when you create LINQ queries, whether you use LINQ to Objects, LINQ to SQL, LINQ to XML, or some other custom LINQ provider. I'll discuss the query keywords, how those keywords map to methods defined using the query operands, and how you can define your own custom implementation for the query keywords.
One of the design goals of the C# language (and most computer programming languages) is to keep the set of keywords small. Fewer keywords means there's more vocabulary available for your types, members, and other user-defined identifiers. It also simplifies the job of understanding the language. The C# team worked to minimize the necessary grammar for LINQ and the associated query syntax. They ended up adding eight contextual keywords to the C# language specifically for query: from, where, select, group, into, orderby, join, and let.
The C# team also saw type inference as a major goal of the new release. The C# language is still strongly typed: every identifier has a known type, at least to the compiler. However, a developer must declare the type explicitly only when the compiler cannot make its own determination of the variable's type. In many cases, the compiler determines the proper type for you.
Every query expression begins with the "from" keyword. From introduces a query expression by declaring the datasource and range variable. This snippet defines a simple query:
int[] someNumbers = { 2, 3, 7, 11, 13, 17, 19 }; var query = from number in someNumbers
someNumbers is the datasource, and number is the range variable. The datasource must implement IEnumerable, or IEnumerable. In this example, someNumbers implements IEnumerable. The compiler gives the range variable a type to match the type enumerated by the datasource. In the example above, number will be an integer. In general, the range variable is of type T, whenever the datasource implements IEnumerable. In the case where the range variable implements IEnumerable, the range variable is a System.Object. You never need to declare the type of the range variable; the compiler infers it.
Do More with "From" The "from" clause can do much more than iterate a single sequence. Often, an outer sequence will contain an inner sequence that contains the data you're interested in. You can nest from clauses to create the sequence of elements from the inner sequences . Using multiple from clauses when the second datasource isn't a member of the first range variable will do a cross-join. This simple expression produces 25 pairs of values, ranging from {1,2} through {9,2} on to {1,10}, and, finally, through {9,10}:
var pairs = from even in evenNumbers from odd in odddNumbers select new { even, odd };
foreach (var pair in pairs) Console.WriteLine( " odd = {0}, even = {1}", pair.odd, pair.even);
This from clause generates every permutation of a value from the first sequence value, and then pairs it with a value from the second sequence. Of course, you're not limited to two sources. You could do an N-way cross-join for any number N. Just remember that the size of the result set will grow geometrically as you add more source sequences.
The next new keyword is select. Select determines what type of object or objects are returned by your query. Select is powerful enough to create whatever types you want, including anonymous types, as the output of a query. Select projects the values you want into the output of a query. You've already seen two examples of the select statement. Listing 1 showed a simple select that returns the same type as the input query. The immediately preceding code snippet illustrating the cross-join shows an example of a select that transforms the input type into another type. In that case, it creates a new type containing a number from the first sequence and a number from the second sequence. The compiler does quite a bit of work for you in that example. The compiler infers the shape of the items in the output sequence, and it creates an anonymous type matching that description. The output sequence contains values of that anonymous type. It sounds more difficult than it really is. In that example, the compiler creates a type that contains two integers: odd and even. Those integers are accessed through public read-only properties. The compiler writes a type similar to the type you would have created by hand.
In general, you can use the select keyword to transform the values in the query into any type you decide you want for the output from the query. You'll see this feature at work in several of this article's examples. For instance, you'll see that you can compute values as part of the output, combine multiple inputs into a single output stream, generate new types, or almost anything else. Select is quite powerful because its argument is an arbitrary lambda expression that can return anything computed from the input sequence.
Filter the Input Sequence Another keyword you'll use frequently is where. Where filters the input sequence and passes only those values that match the condition specified by the where predicate. You can place where clauses almost anywhere in your query expression. The only restrictions are that it must not be first, nor can it be last. For example, assume you want to filter the input sequence so it returns only those values greater than five:
var query = from number in someNumbers where number > 5 select number;
Where clauses can also be more complicated. For example, you can combine multiple conditions into a single where clause:
var query = from number in someNumbers where number > 5 && number * number
An alternative approach is to express the same construct with multiple where clauses:
var query = from number in someNumbers where number > 5 where number * number
Where works the same way even when there are multiple sources, and you want to provide filters on those elements. All these query expressions produce the same result:
var pairs1 = from even in evenNumbers where even > 4 from odd in odddNumbers where odd < pairs2 =" from"> 4 where odd < pairs2 =" from"> 4 && odd
In general, you should consider placing where clauses as early as possible in your queries. Later clauses in your query operate on a smaller set of data.
Another new query keyword is orderby. Orderby creates an ordering of the output sequence. You can order the output elements on any expression that's part of the input sequence, even if that element isn't part of the output sequence, or by an element that's computed from part of the input sequence.
This query sorts the list of names by the length of the name and then by alphabetical order:
var folks = from person in myPeeps orderby person.Last.Length + person.First.Length descending, person.Last, person.First select string.Format("{0}, {1}", person.Last, person.First);
The first orderby arranges the sequence of elements from longest to shortest. In the case of ties, the last name will be used to order the people. If there are still any ties, the first name will be used. Note that I've also transformed the person object into a string in the select statement.
As I mentioned earlier, the select statement can create any output type you wish. In most cases, I like to put the orderby clauses as late in the query expression as possible. Orderby needs the full sequence to do its work, so it creates a natural bottleneck on the sequence processing.
Subdivide the Results Occasionally, you'll use the group clause to subdivide the results of the query into logical groupings. You could modify the previous query by grouping the names by the length of the first name:
var folks = from person in myPeeps group person by person.First.Length into names orderby names.Key select names;
There are a number of new ideas here, so let's look at them closely. This group expression creates subdivisions based on the length of the first name of each person. It's common to want to perform further processing on each group. Therefore, you'll often see an "into" following the group clause. The into keyword assigns a name to each grouping. In the above example, that grouping is called "names." Next, you see the familiar orderby clause to order the groups based on the key assigned to each group. The Key is the value of the "by" portion of the group clause. In this example, the Key is an integer, which stores the length of the first names in the group.
The result sequence of the query uses a different type when you add the group clause. The results for a group clause are stored in an IEnumerable> sequence. That's a sequence of groups. For each element, the Key element stores the key, and the IGrouping implements IEnumerable so that you can iterate the values in each group.
You use the join clause to perform equijoins. An equijoin creates a single sequence from two different input sequences based on an equality test of some property in both sequences. There are three different variations of join. Join is most easily illustrated in the context of LINQ to SQL, so these examples are taken from the Sample Queries sample application that ships with Visual Studio 2008. They perform joins on different tables in the Northwind database.
This query performs an inner join between the categories and products tables to produce a single sequence with the products and categories listed:
var q = from c in db.Categories join p in db.Products on c.ID equals p.CategoryID select new {productName = p.ProductName, categoryName = c.Name};
This code snippet creates a single sequence that contains the product name and category name. If a category doesn't have any matching products, that category doesn't appear in the output.
If you use the into keyword with your join clause, you create a group join. Similar to the groupby clause, a group join creates a list of lists for each group. In that same vein, you could create a list of all categories where each element contains the list of all products in that category:
var q = from c in db.Categories join p in db.Products on c.ID equals p.CategoryID into productGroup select new {categoryName = c.Name, Products =productGroup};
The only noticeable difference is the addition of the into keyword to create a set of groups. However, when you use the group join, any of the elements on the left side source won't appear in the output sequence unless there are matching elements in the right input sequence. In the preceding example, that means any categories with no products won't appear in the output sequence. To fix that, you need the left outer join. That requires using the DefaultIfEmpty method. This variation returns all categories, even those with no products:
var q = from c in db.Categories join p in db.Products on c.ID equals p.CategoryID into productGroup from aproduct in productGroup.DefaultIfEmpty() select new {categoryName = c.Name, Product =aproduct};
The left outer join produces a single, flat sequence, like the inner join. The element will contain the category and the product. In the approach used here, the product will be null if there are no products associated with a given category.
Only one keyword remains--let. Let creates a new range variable in the query expression. You can use this for a couple different purposes. First, if the new range variable is an enumerable type, it can be queried. Alternatively, it can store the result of some computation to avoid recomputing it.
Let's look at this keyword in action.
Suppose you want to modify the pair of numbers sample to keep only those pairs of numbers where the distance from the origin is less than 10. You could modify the query this way:
var pairs = from even in evenNumbers from odd in odddNumbers where Math.Sqrt( even * even + odd * odd)
That's fine, but now assume you also want to include the distance from the origin in the output sequence. You could write it this way, but you'd be computing the distance twice for every value:
var pairs = from even in evenNumbers from odd in odddNumbers where Math.Sqrt(even * even + odd * odd) < distance =" Math.Sqrt(even">
This is a great place to use the let clause. You can rewrite the clause this way so that you have to compute the distance only once:
var pairs = from even in evenNumbers from odd in odddNumbers let distance = Math.Sqrt(even * even + odd * odd) where distance
The second use of let is less common. If your interim calculation produces a sequence, you could use that range variable in a from clause and process each element in the sequence.
Map Keywords to Methods That's all the new queries that support query expressions. Most of these new keywords compile to method calls. Where compiles to a call to the Where() method. Select compiles to a call to the Select() method. The first orderby compiles to a call to the OrderBy() method. Subsequent calls compile to ThenBy(). If the orderby clauses include the descending keyword, the methods called are OrderByDescending() and ThenByDescending(). Group clauses translate into the GroupBy() method calls. Join usually compiles to a call to Join(); if it's followed by "into," it compiles to a GroupJoin() method.
The .NET 3.5 base class library contains versions of each of these methods in two different classes: System.Linq.Queryable and System.Linq.Enumerable. The versions in Enumerable are defined so that the standard query operators can be used in any sequence. The Queryable version is used when the source supports IQueryable.
This might not sound so important, but there's a good reason for you to understand that these keywords map to specific methods: They're methods, so you can define your own version for your own types if you can create a better version than the default. The default versions are defined as extension methods, which means that any version you write will probably be a better match.
The standard query operators are general methods. Each of them takes expression trees, so you're signing up for quite a bit of work when you define your own versions of these. You'll more likely define your own versions of other extension methods defined in Queryable or Enumerable. Obvious examples are Take and Skip. You might use Skip to implement any container implementing IList:
public static IEnumerable Skip(IList sequence, int count) { for (int i = count; i <>
Note that you can avoid any number of MoveNext calls by using the indexing operator.
Similarly, you could add your own versions of any of the methods defined in System.Linq.Enumerable, where you had a more efficient way of computing the answer.
Earlier in this article, I mentioned that these new keywords are contextual keywords. That's important for backward compatibility with existing programs. These new keywords are only reserved words when they appear in the proper location. These variable declarations are all legal C# 3.0:
int where = 5; string select = "This is a string"; int var = 7;
That's because the keywords where, select, and var aren't appearing in the proper context for the compiler to view them in their special new way.
This might also seem like language geek trivia, but it's important for most developers. The C# team worked hard to ensure that these new additional features wouldn't break existing programs. By making these new keywords contextual keywords, they were able to introduce new syntax, while minimizing the chance of breaking any existing C# code. None of this new syntax will break your existing code.
When working in Visual Studio 2008 and the IntelliSense pop-up is visible, but you would like to view the code that is covered by it, press and hold the Ctrl key, and the pop-up becomes transparent so that you can view the code that is below the pop-up.
Take advantage of functional programming techniques like Filter, Map, and Reduce in your day-to-day business apps.
TECHNOLOGY TOOLBOX: C#, SQL Server 2005 Compact Edition Runtime, Visual Studio 2005 Standard Edition SP1 or Higher, SQL Server Management Studio [Express] SP2
As you start using C# 3.0, you'll find yourself diving deeper into the concepts created for functional programming. This is the academic research done for languages like LISP, ML, Haskell, and others that have only a small installed base in professional programming environments. In a way, that's too bad, because many of these concepts provide elegant solutions to many of the
The incorporation of these functional programming techniques into .NET is one of the reasons why I'm excited about the release of C# 3.0 and Visual Studio (VS) 2008. You can use these same concepts in your favorite language. That's important for a couple of reasons. First, you're more familiar with the syntax of your preferred language and that makes it much easier to continue being productive. Second, you can mix these functional programming concepts alongside more traditional imperative algorithms.
Of course, you also give something up by staying in your familiar environment. Doing things the way you're accustomed to doing them often means that you're slow to try and adapt new techniques. Other times, you might not get the full advantage of a given technique because you're using it in your familiar context, and that context doesn't take full advantage of the technique.
This article will familiarize you with three of the most common functional programming elements: the higher order functions Filter, Map, and Reduce. You're probably already familiar with the general concepts--if not the specific terms--so much of the research associated with functional programming will be fairly accessible.
Define a Value's Removal You've already used the concept of Filter, even in C# 2.0. List contains a RemoveAll() method. RemoveAll takes a delegate and that delegate determines which values should be removed from your collection. For example, this code removes all integers from the someNumbers collections that are divisible by 3:
List someNumbers = new List { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 };
C# 3.0 provides a more concise way to express that same concept:
someNumbers.RemoveAll(num => num % 3 == 0);
That's a filter. The filter defines when to remove a value. Let's take a small detour into vocabulary land. A Higher-Order function is simply a function that takes a function as a parameter, or returns a function, or both. Both of these samples fit that description. In both cases, the parameter to RemoveAll() is the function that describes what members should be removed from the set. Internally, the RemoveAll() method calls your function once on every item in the sequence. When there's a match, that item gets removed.
In C# 3.0 and Language Integrated Query (LINQ) syntax, the Where clause defines the filter. In the case of Where, the filter expression might not be evaluated as a delegate. LINQ to SQL processes the expression tree representation of your query. By examining the expression tree, LINQ to SQL can create a T-SQL representation of your query and execute the query using the database engine, rather than invoking the delegate. Any provider that implements IQueryable or IQueryable will parse the expression tree and translate it into the best format for the provider.
A filter is the simplest form of a higher order function. Its input is a sequence, and its output is a proper subset of the input sequence. The concept is already familiar to you, and it shows the fundamental concept of passing a function as a parameter to another function.
C# 2.0 and the corresponding methods in the .NET framework did not fully embrace the concepts of functional programming. You can see that in the way RemoveAll is implemented. It's a member of the List class, and it modifies that object. A true Filter takes its input sequence as a parameter and returns the output sequence; it doesn't modify the state of its input sequence.
Return a New Sequence Map is the second major building block you'll see in functional programming. Map returns a new sequence computed from an input sequence. Similar to Filter, Map takes a function as one of its parameters. That function transforms a single input element into the corresponding output element.
As with Filter, there's similar functionality in the .NET base library. List.ConvertAll produces a new list of elements using a delegate you define that transforms a single input element into the corresponding output element. Here, the conversion computes the square of every number:
List someNumbers = new List { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 }; List squares = someNumbers.ConvertAll( delegate(int num) { return num * num; }); squares.ForEach(delegate(int num) { Console.WriteLine(num); });
In C# 3.0, lambda syntax makes this more concise:
List squares = someNumbers.ConvertAll(num => num * num);
Filter is built in to the query syntax added in C# 3.0:
IEnumerable squares = from num in someNumbers select num * num;
Of course, you probably noticed that quick change in the last code snippet. The last version returned an IEnumerable rather than a List. The C# 3.0 versions of these methods operate on sequences, and aren't members of any particular type.
There's nothing that says the output sequence has to be of the same type as the input sequence. This method returns a list of formatted strings computed from a set of input numbers:
List someNumbers = new List { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 }; List formattedNumbers = someNumbers.ConvertAll( delegate(int num) { return string.Format("{0:D6}", num); }); formattedNumbers.ForEach( delegate(string num) { Console.WriteLine(num); });
Of course, the same method gets simplified using C# 3.0:
List formattedNumbers = someNumbers.ConvertAll (num => string.Format("{0:D6}", num)); And can be further simplified using the query syntax:
IEnumerable formattedNumbers = from num in someNumbers select string.Format("{0:D6}", num);
As with Filter, you've used functionality like Map before. You might not have known what it was called, or where its computer science roots lie. Filter is nothing more than a convention where you write a method that converts one sequence type into another, and the specifics of that conversion are coded into a second method. That second method is then passed on as a parameter to the Map function.
One Function to Rule Them All: Reduce The most powerful of the three concepts I'm covering this month is Reduce. (You'll also find some references that use the term "Fold.") Reduce returns a single scalar value that's computed by visiting all the members of a sequence. Reduce is one of those concepts that is much simpler once you see some examples.
This simple code snippet computes the sum of all values in the sequence:
List someNumbers = new List { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 }; int sum = 0; foreach (int num in someNumbers) sum += num; Console.WriteLine(sum);
This is simple stuff that you've written many times. The problem is that you can't reuse any of it anywhere. Also, many other examples will likely contain more complicated code inside the loop. So smart computer science wizards decided to take on this problem and create a way to pass along that inner code as a parameter to a generic method. In C# 3.0, the answer is the Aggregate extension method. Aggregate has a few overloads. This example uses the simplest form:
List someNumbers = new List { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 }; int sum = someNumbers.Aggregate( delegate(int currentSum, int num) { return currentSum + num; }); Console.WriteLine(sum);
The delegate continues to produce a running sum from the current value in the sequence, as well as the total accumulated so far. There are two other overloads of Aggregate. One takes a seed value:
int sum = someNumbers.Aggregate(0, delegate(int currentSum, int num) { return currentSum + num; });
The final overload allows you to specify a different return type. Suppose you wanted to build a comma-separated string of all the values. You'd use the third version of Aggregate:
List someNumbers = new List { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 }; string formattedValues = someNumbers.Aggregate(null, delegate(string currentOutput, int num) { if (currentOutput != null) return string.Format("{0}, {1}", currentOutput, num); else return num.ToString(); }); Console.WriteLine(formattedValues);
Of course, all of these can be rewritten using lambda syntax:
The second example converts the numbers to a list of strings, and it's a bit more complicated code. But it's all stuff you've seen before. The second example uses only the ternary operator to do the test. If this makes you uncomfortable, you can use the imperative syntax with lambda expressions:
Earlier, I paraphrased Tolkien, and called Reduce the one function to rule them all. From a computer science perspective, Filter and Map are nothing more than special cases of Reduce. If you define a Reduce method where the return value type is a sequence, you can implement Map and Filter using Reduce.
However, most libraries don't work that way because Map and Filter can perform much better if they don't share code with Reduce. And the Filter and Map prototypes are quite a bit simpler to understand.
This column contained some low-level concepts that will help you understand the computer science upon which C# 3.0, LINQ, and much of the .NET 3.5 Framework were built. It's all stuff you've seen before, and it's not that difficult. It's just that they come with new twists and more concise code around what you've already been doing.
+(2).PNG)